Zadowolony
- Historia rozwoju
- Zasady budowy
- Terminy i rodzaje
- Struktury alternatywne
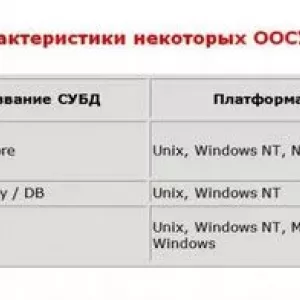
- Przykłady relacyjnych DBMS
- System zarządzania RDBMS
- Różnice między RDBMS a konwencjonalnym DBMS
- Tabela strukturalna
- Klucze podstawowe
- Model sieciowej bazy danych
- System zorientowany obiektowo
- proces projektowania
- Tworzenie bazy danych programu Access
System zarządzania relacyjną bazą danych System RDBMS to w zasadzie nic innego jak komputerowy system, który może przechowywać dane. Użytkownicy otrzymują środki do wykonywania kilku rodzajów operacji na danych w bazie lub do zarządzania jej strukturą. RDBMS są klasyfikowane według struktury.
Historia rozwoju

Relacyjna baza danych RDBMS została wynaleziona na początku lat 70-tych przez E. Ф. Codd, młody naukowiec z IBM zajmujący się oprogramowaniem. W specjalnym artykule na temat RDBMS zaproponował odejście od przechowywania danych w strukturach hierarchicznych na rzecz organizowania ich w tabelach z wierszami i kolumnami.
Do lat 60-tych XX wieku ogromna ilość danych została zgromadzona na nowych komputerach mainframe na świecie, z których wiele było komputerami IBM System 360. Stanowiło to wyzwanie dla ciągłego rozwoju technologii cyfrowych. Obliczenia na mainframe były drogie, często kosztowały setki dolarów za minutę. Istotną część tych kosztów stanowiła złożoność związana z zarządzaniem bazą danych (DB).
W 1973 roku w laboratorium w San Jose, obecnie Almaden, rozpoczęto prace nad programem o nazwie System R (relational), który miał na celu zastosowanie teorii relacyjnej w implementacji przemysłowej. Jakość ta jest cechą definiującą to, co nazywane jest relacyjnym DBMS. W wyniku tego projektu powstał nowy, rewolucyjny system pamięci masowej, który stał się podstawą sukcesu firmy IBM.
Don Chamberlin i Ray Boyce wymyślili SQL dla danych strukturalnych, który jest dziś najczęściej używany. Patricia Selinger opracowała optymalizator oparty na kosztach, który czyni pracę z relacyjnymi bazami danych bardziej opłacalną i wydajną. A Raymond Laurie wymyślił kompilator do zapisywania procedur zapytań do bazy danych do przyszłego użytku.
W 1983 roku IBM wprowadził drugą rodzinę relacyjnych DB2 DBMS przeznaczonych do zarządzania danymi. Dziś DB2 nadal generuje miliardy transakcji każdego dnia, co czyni go najbardziej udanym oprogramowaniem IBM. Według Arvinda Krishny, dyrektora generalnego IBM Information Management, DB2 pozostaje liderem w dziedzinie innowacyjnego oprogramowania relacyjnych baz danych (RDBMS).
Dr Codd, znany swoim kolegom jako Ted, otrzymał w 1976 roku stypendium IBM, a w 1981 roku Association for Computing Machinery przyznało mu nagrodę Turinga za wkład w rozwój RDBMS.
Zasady budowy
Każda tabela, zwana również relacją w relacyjnej bazie danych RDBMS, zawiera jedną lub kilka kategorii danych w kolumnach atrybutów. Każdy wiersz nazywany jest rekordem lub krotką, zawiera unikalną instancję danych lub klucz dla kategorii określonych przez kolumny. Tabela ma unikalny klucz główny, który identyfikuje informacje w niej zawarte. Relacja między tabelami jest tworzona przez użycie kluczy obcych odwołujących się do kluczy podstawowych innej tabeli.
Na przykład, typowa relacyjna baza danych zamówień biznesowych posiada tabelę opisującą klienta, z kolumnami dla nazwiska, adresu, numeru telefonu i innych informacji. Następny ma tabelę porządkującą: produkt, klient, data, cena sprzedaży, i tak dalej. Użytkownik RDBMS otrzymuje widok bazy danych zgodny z jego potrzebami. Na przykład, kierownik oddziału może chcieć wyświetlić lub zgłosić wszystkich klientów, którzy zakupili towary po określonej dacie. Specjalista ds. obsługi finansowej w tej samej firmie dostaje z tych samych tabel raport faktur do zapłaty.
Terminy i rodzaje

Relacyjne DBMS zawierają tabele zawierające wiersze i kolumny. Podczas tworzenia RDB należy określić zakres możliwych wartości w kolumnie danych oraz dodatkowe ograniczenia, które można zastosować do tej wartości. Na przykład domena klienta może dopuszczać do 10 możliwych nazw, ale w pojedynczej tabeli może być ograniczona tylko do trzech z tych nazw klientów. Dwa ograniczenia dotyczą integralności danych oraz kluczy podstawowych i obcych. Integralność obiektu zapewnia, że klucz główny jest unikalny i że wartość nie jest zerowa. Integralność referencyjna wymaga, aby każda wartość w kolumnie klucza zewnętrznego znajdowała się w kluczu podstawowym tabeli, z której pochodzi.
Istnieje wiele kategorii baz danych: od prostych płaskich plików, które nie są związane z NoSQL, po nowsze, oparte na grafach, które są uważane za jeszcze bardziej relacyjne niż standardowe bazy danych. Płaska baza danych składa się z pojedynczej tabeli, która nie posiada żadnych relacji, zazwyczaj są to pliki tekstowe. Pozwala użytkownikom określić atrybuty danych, takie jak kolumny i typy w relacyjnych SZBD.
Struktury alternatywne

Baza danych NoSQL to alternatywa dla RDBMS, która jest szczególnie przydatna do pracy z dużymi zbiorami rozproszonych danych.
Baza danych grafów wykracza poza tradycyjne relacyjne modele danych oparte na kolumnach i wierszach. NoSQL posiada węzły i krawędzie, które reprezentują połączenia między relacjami danych i odkrywają nowe między nimi. RDBMS są bardziej złożone niż RDBMS, stąd ich zastosowanie obejmuje mechanizmy wykrywania oszustw lub reputacji w sieci.
Przykłady relacyjnych DBMS

SQLite jest popularną bazą danych SQL typu open source. Oprogramowanie może przechowywać całą bazę danych w jednym pliku. Najważniejszą zaletą jest to, że wszystkie dane mogą być przechowywane lokalnie bez konieczności łączenia się z serwerem. SQLite stał się popularny dla baz danych w telefonach komórkowych, PDA, odtwarzaczach MP3, dekoderach i innych gadżetach elektronicznych.
MySQL jest innym popularnym open-source`owym relacyjnym systemem zarządzania bazą danych SQL. Jest on powszechnie stosowany w aplikacjach internetowych i często jest dostępny za pomocą PHP. Jego główne zalety to łatwość użycia, przystępna cena, niezawodność. Niektóre z wad to, że cierpi na słabą wydajność przy skalowaniu, rozwój open-source jest opóźniony od czasu Oracle przejął kontrolę nad MySQL i nie zawiera niektórych zaawansowanych funkcji.
PostgreSQL to model relacyjnej bazy danych SQL o otwartym kodzie źródłowym, który nie jest kontrolowany przez żadną korporację. Jest on zazwyczaj używany do tworzenia aplikacji internetowych. PostgreSQL jest prosty, niezawodny i przyjazny dla budżetu oraz posiada dużą społeczność programistów. Posiada dodatkowe funkcje w postaci obsługi kluczy zewnętrznych, bez konieczności skomplikowanej konfiguracji. Jego główną wadą jest to, że jest wolniejszy niż inne bazy danych, takie jak MySQL. Jest również mniej popularny niż MySQL, co sprawia, że hosty i dostawcy usług oferujący zarządzane instancje PostgreSQL są trudni do pokonania.
System zarządzania RDBMS
RDBMS to system zarządzania relacyjną bazą danych opracowany przez EF Codd z IBM, umożliwiający tworzenie, modyfikowanie i administrowanie RDBMS. Wiele istniejących dziś baz danych to rozszerzenia tego wiekowego modelu. Przechowywane dane są przetwarzane przy użyciu operatorów relacyjnych RDBMS.
SQL jest używany jako język zapytań do bazy danych - jest to logiczna grupa danych. Zawiera zestaw połączonych przestrzeni tabel i indeksów. Zazwyczaj baza danych zawiera wszystkie dane związane z pojedynczą aplikacją lub powiązaną grupą. Na przykład może to być baza danych płac lub zapasów.
Różnice między RDBMS a konwencjonalnym DBMS

RDBMS przechowuje dane w postaci plików, natomiast RDBMS przechowuje dane w postaci tabeli. RDBMS umożliwia normalizację danych, a RDBMS utrzymuje relacje między danymi przechowywanymi w swoich tabelach. RDBMS nie dostarcza referencji. Po prostu przechowuje dane w swoich plikach. Podejście strukturalne RDBMS obsługuje rozproszony RDBMS, w przeciwieństwie do konwencjonalnego systemu zarządzania bazą danych. RDBMS skupia się na szerokim zakresie zastosowań, jego cechy pozwalają na wykorzystanie go na całym świecie.

RDBMS Cechy:
- Implementacja wspólnej kolumny, jak również dostęp wielu użytkowników są zawarte w cechach RDBMS.
- Potencjał tego relacyjnego modelu DBMS został więcej niż uzasadniony przez dzisiejsze możliwości zastosowań.
- Lepsze bezpieczeństwo zapewnia tworzenie tabel.
- Niektóre tabele mogą być chronione przez system.
- Użytkownicy mogą ustawić bariery dostępu do treści. Jest to bardzo przydatne w firmach, gdzie kierownik może decydować o tym, jakie dane są udostępniane pracownikom i klientom. W ten sposób można ustalić indywidualny poziom ochrony danych.
- Przyszłość, ponieważ nowe dane można łatwo dodać do istniejących tabel i uzgodnić z wcześniej dostępną zawartością. Jest to cecha, której nie posiada żadna inna płaska baza danych.
Tabela strukturalna
Tabela to struktura logiczna składająca się z wierszy i kolumn. Wiersze nie mają stałej kolejności, więc jeśli dane są pobierane, może być konieczne ich posortowanie. Kolejność kolumn jest określana podczas tworzenia tabeli przez administratora bazy danych. Na przecięciu każdej kolumny i wiersza znajduje się określony element danych zwany wartością, a dokładniej wartością atomową. Tabela jest nazywana za pomocą wysokopoziomowego klasyfikatora ID użytkownika właściciela, po którym następuje nazwa tabeli, np. TEST.DEPT lub PROD.DEPT.
Istnieje kilka rodzajów stołów:
- Baza - która jest tworzona i zawiera stałe dane.
- Tymczasowy, który przechowuje pośrednie wyniki zapytania.
Elementy tabeli:
- Kolumny mają zbiór uporządkowany: DEPTNO, DEPTNAME, MGR i ADMK DEPT. Wszystkie muszą być tego samego typu danymi.
- Wiersze - każdy zawiera dane dla jednego działu.
- Wartości na przecięciu kolumny i wiersza. Na przykład PLANNING to wartość kolumny DEPT NAME w wierszu dla działu B01.
Indeks jest uporządkowanym zbiorem wskaźników do wierszy tabeli. W przeciwieństwie do wierszy tabeli, które nie mają określonej kolejności, indeks DB2 musi zawsze zachować porządek.
Indeks służy do dwóch celów:
- Dla szybszego wyszukiwania wartości danych.
- Dla unikalności.
Tworząc indeks według nazwiska pracownika, możesz pobrać dane dla tego pracownika szybciej niż skanując całą tabelę. Dodatkowo, tworząc ją, DB2 zapewni, że każda wartość jest unikalna. Utworzenie indeksu powoduje automatyczne utworzenie przestrzeni indeksowej, zbioru danych, który go zawiera.
Klucze podstawowe

Klucz to jedna lub kilka kolumn określonych jako takie podczas tworzenia definicji integralności referencyjnej. Tabela ma tylko jeden klucz główny, ponieważ definiuje encję. Są na to wymagania:
- Musi mieć wartość, czyli nie może być null.
- Musi mieć unikalny indeks.
- Może mieć więcej niż jeden unikalny klucz w tabeli.
- klucz obcy - klucz obcy określony w ograniczeniu integralności referencyjnej tak, że jego istnienie zależy od klucza głównego lub nadrzędnego.
Model sieciowej bazy danych
Ta baza danych pozwala, aby rekordy miały wiele formatów rodziców i dzieci, które mogą być wizualizowane jako struktura sieciowa. W przeciwieństwie do tego, element hierarchicznej relacyjnej bazy danych ma wiele dzieci i jednego rodzica. W rzeczywistości model sieciowy jest bardzo podobny do modelu hierarchicznego, będąc jego podzbiorem. Jednak zamiast używać jednego rodzica, model sieciowy wykorzystuje teorię zbiorów, aby zapewnić hierarchię podobną do drzewa. Wyjątkiem jest to, że tabele dziecięce mogą mieć więcej niż jednego rodzica.
Zalety sieciowej bazy danych:
- Koncepcyjnie proste i łatwe do opracowania.
- Dostęp do danych jest prostszy i bardziej elastyczny niż w modelu hierarchicznym i nie pozwala na istnienie członka bez rodzica.
- Może obsługiwać złożone dane dzięki relacji wiele do wielu. Pozwala to na bardziej naturalne modelowanie relacji pomiędzy rekordami lub obiektami w relacyjnym DBMS, w przeciwieństwie do hierarchicznego.
- można łatwiej przemieszczać się i znajdować informacje w sieciowej bazie danych ze względu na jej elastyczność.
- Struktura ta izoluje programy sterujące od złożonych danych fizycznych.
System zorientowany obiektowo
W obiektowej bazie danych wszystkie dane są obiektami. Mogą być one połączone ze sobą relacją "jest częścią", aby reprezentować większe części składowe.
Na przykład dane opisujące pojazd mogą być przechowywane w obiektowej bazie danych jako kompozyt Część konkretnego silnika, podwozia, skrzyni biegów, układu kierowniczego itp.". Klasy obiektów mogą tworzyć hierarchię, w której poszczególne obiekty dziedziczą właściwości z obiektów znajdujących się powyżej. Na przykład, wszystkie obiekty klasy "pojazd mechaniczny" będą miały silnik (ciężarówka, samochód lub samolot). Podobnie silniki są również obiektami danych, a atrybut silnika dla danego pojazdy będzie odniesieniem do konkretnego obiektu silnika.
Multimedialne bazy danych, w których głos, muzyka i wideo są przechowywane razem z tradycyjnymi informacjami tekstowymi, służyć jako podstawa przeglądać dane jako obiekty. Takie obiektowe bazy danych stają się coraz ważniejsze, ponieważ ich struktura jest najbardziej elastyczna i przystosowawcza. To samo dotyczy baz danych obrazów, zdjęć czy map. Przyszłość technologii baz danych jest zwykle postrzegana jako integracja modeli relacyjnych i obiektowych.
proces projektowania

Projektowanie baz danych jest bardziej sztuką niż nauką, więc jako użytkownik muszą podejmować wiele decyzji. Bazy danych są zwykle dostosowywane do konkretnego zastosowania. Żadne dwie aplikacje użytkownika nie są takie same, a zatem żadne dwie bazy danych nie są takie same. Wytyczne zwykle wskazują, czego nie należy robić, choć wybór należy ostatecznie do projektanta.
Algorytm projektowania:
- Określenie przeznaczenia bazy danych do analizy wymagań.
- Gromadzenie wymagań. Zbieranie danych, organizowanie tabel i określanie kluczy głównych.
- Wybierz jedną lub więcej kolumn jako tzw. klucz główny w celu identyfikacji wierszy.
- Tworzenie relacji między tabelami. Siła relacyjnej bazy danych leży w relacjach między tabelami. Najważniejszym aspektem przy tworzeniu RDBMS jest określenie relacji między nimi.
- Należy wybrać wymagany typ danych dla danej kolumny. Typy danych zazwyczaj zawierają: liczby całkowite, string (lub tekst), datę, czas, binarne, kolekcje, takie jak enumeration i set.
- Ulepszanie projektu poprzez dodawanie kolejnych kolumn.
- Tworzenie nowej tabeli dla danych opcjonalnych przy użyciu relacji jeden do jednego.
- Podziel duży stół na dwa mniejsze biurka.
- Zastosuj reguły normalizacji, aby sprawdzić, czy baza danych jest strukturalnie poprawna i optymalna.
- Indeks może być zdefiniowany dla pojedynczej kolumny, zestawu kolumn zwanego indeksem złożonym, lub części kolumny zwanej indeksem częściowym. Możesz stworzyć więcej niż jeden indeks w tabeli. Na przykład, jeśli często szukasz klienta używając albo nazwy klienta albo numeru telefonu, możesz przyspieszyć wyszukiwanie konstruując indeks na kolumnie nazwa klienta jak również numer telefonu.
- Większość baz danych automatycznie buduje indeks na podstawie klucza głównego.
Tworzenie bazy danych programu Access
W przypadku korzystania z relacyjnej bazy danych Access nie można po prostu rozpocząć procesu wprowadzania danych. Zastosuj projekt RDBMS dzieląc blok informacyjny na szereg tabel. Są one łączone za pomocą złączeń relacyjnych, gdzie pole jednej z nich jest takie samo jak pole drugiej tabeli.
Algorytm tworzenia DB:
- Wstępne zdefiniowanie danych i sporządzić listę Organizowanie pól (fragmentów informacji) przy użyciu różnych typów danych.
- Wyeliminowanie zbędnych pól. Nie przechowuj identycznych informacji w więcej niż jednym miejscu. W przypadku gdzie możliwe jest obliczyć jedno pole na podstawie innego, zapisać jedno.
- Uporządkowanie pól. Uformuj je zgodnie z opisem, tak aby każda grupa została zamieniona na tabelę.
- Dodaj tabele kodów ze skrótami.
- Dołączenie do bazy danych tabeli z nazwami i dwuliterowymi kodami.
- Wybierz klucz główny.
- tabele linków.
Można więc podsumować, że główne zalety systemów RDBMS to fakt, że pozwalają one użytkownikom w prosty sposób klasyfikować i przechowywać dane, są łatwo rozszerzalne i nie zależą od fizycznej organizacji. Po utworzeniu początkowej bazy danych można dodać nową kategorię danych bez konieczności zmiany wszystkich istniejących aplikacji.
 Obiektowe bazy danych: pojęcie, podstawowe pojęcia, zarządzanie, przykłady
Obiektowe bazy danych: pojęcie, podstawowe pojęcia, zarządzanie, przykłady Nosql, bazy danych: przegląd, przykłady i zastosowania
Nosql, bazy danych: przegląd, przykłady i zastosowania Klasyfikacja baz danych: opcje, modele danych i kluczowe cechy
Klasyfikacja baz danych: opcje, modele danych i kluczowe cechy Projektowanie zorientowane obiektowo: definicja, zasady i przykłady
Projektowanie zorientowane obiektowo: definicja, zasady i przykłady Cukier syntaktyczny: definicja, pochodzenie i przykłady
Cukier syntaktyczny: definicja, pochodzenie i przykłady Tonik do skóry mieszanej: skład, przegląd producentów, cechy stosowania, recenzje
Tonik do skóry mieszanej: skład, przegląd producentów, cechy stosowania, recenzje Maść z krost podskórnych: przegląd środków, cechy stosowania, skuteczność, recenzje
Maść z krost podskórnych: przegląd środków, cechy stosowania, skuteczność, recenzje Jak wygląda leczenie półpaśca: przegląd leków
Jak wygląda leczenie półpaśca: przegląd leków Rachunek lambda: opis twierdzenia, cechy, przykłady
Rachunek lambda: opis twierdzenia, cechy, przykłady