Zadowolony
W informatyce cukier syntaktyczny to lingwistyka w języku programowania. Został zaprojektowany, aby uczynić kod łatwiejszym, bardziej czytelnym i ekspresyjnym. Ten cukier sprawia, że język jest "słodszy" dla człowieka. To znaczy, że rzeczy mogą być wyrażone wprost, krótko lub w alternatywnym stylu, który niektórzy mogą preferować.
Cukier syntaktyczny: co to jest?

Wiele języki programowania zapewniają specjalny dział gramatyki zajmujący się aktualizacją elementów. W abstrakcji, odwołanie do danego obiektu jest procedurą dwóch argumentów: tablicy i indeksu dolnego, co można wyrazić jako get_array(Array, vector(i, j)). Zamiast tego wiele języków zapewnia składnię np Array [i, j]. Podobnie aktualizacja elementu w tablicy, np, set_array(Array, vector(i, j), value), jest procedurą trzyargumentową, ale wielu profesjonalistów zapewnia taki kod jak Array[i, j] = wartość.
Konstrukcja w języku jest nazywana "cukrem syntaktycznym", jeśli może być usunięta z programu bez wpływu na funkcjonalność lub ekspresyjność.
Różne procesory, w tym kompilatory i parsery statyczne, często rozszerzają osłodzone konstrukcje na bardziej podstawowe urządzenia przed przetwarzaniem. Proces ten nazywany jest "deagregacją".
Origins
Termin "cukier syntaktyczny" został ukuty przez Petera J. Hughesa, który jest autorem artykułu. Landin w 1964 roku do opisu działu gramatyki powierzchniowej prostego ALGOL-a, języka programowania, który był zdefiniowany semantycznie w kategoriach wyrażeń aplikacyjnych lambda-calculus, skupiając się na leksykalnym zastąpieniu λ przez "gdzie".
Nowsze języki programowania, takie jak CLU, ML i Scheme, rozszerzyły termin, aby odnieść się do derywacji w języku, który można zdefiniować jako cukier syntaktyczny w zakresie podstawowych konstruktów. Wygodne funkcje wyższego poziomu mogą być "zdezagregowane" i rozłożone na podzbiory. Jest to zresztą powszechna matematyczna praktyka konstruowania z prymitywów.
Opierając się na rozróżnieniu Landina między podstawowymi konstrukcjami językowymi a właściwościami cukru syntaktycznego, w 1991 roku Matthias Fellisen zaproponował kodyfikację "mocy ekspresyjnej", aby dostosować się do szeroko rozpowszechnionych w literaturze przekonań. Określił on jest jak "bardziej znaczący", aby wskazać, że bez danych konstrukcji językowych program powinien zostać całkowicie przeorganizowany.
Słynne przykłady cukru syntaktycznego

W języku COBOL wiele pośrednich słów kluczowych jest "słodkich", to znaczy, że można je pominąć w razie potrzeby. Na przykład, zdanie MOVE A B. i PRZESUNIĘCIE A DO B. spełniają dokładnie tę samą funkcję, ale druga sprawia, że czynność, która ma być wykonana, jest bardziej przejrzysta.
Rozszerzone operatory przypisania złożonego: np. a += b jest równoważne a = a + b w C i podobnych językach, zakładając, że a nie ma efektów ubocznych, takich jak a będące zwykłą zmienną if.
W Perlu, chyba że (warunek) {...} jest składniowo if (not condition) {...}. Ponadto po każdym operatorze może wystąpić warunek, że stwierdzenie, czy warunek równoważny if (warunek) {stwierdzenie}, ale ten pierwszy jest bardziej naturalnie sformatowany w pojedynczej linii.
W C wskaźniki do początku elementu pamięci mogą być pisane bez specjalnej składni: *(a + i). Chociaż w tym języku istnieje specyficzna składnia dla tego procesu: a[i]. Podobnie, a->x, wpis jest cukrem syntaktycznym umożliwiającym dostęp do elementów za pomocą operatora dereferencji (*a). x.
Korzystanie z
Oświadczenie w języku C # zapewnia, że niektóre obiekty są usuwane poprawnie. Kompilator rozszerza to stwierdzenie do bloku try-finally.
Język C # pozwala na deklarowanie zmiennych jako var x = expr, co pozwala kompilatorowi wyprowadzić typ x z wyrażenia expr, zamiast wymagać wyraźnej deklaracji.
Listy zawierają również cukier syntaktyczny Pythona (np, [x*x for x in range (10)] dla listy kwadratów) i dekoratorów (@staticmethod).
W Haskell ciąg oznaczony cudzysłowami jest semantycznie równoważny liczbie znaków.
W pakiecie rvest można znaleźć oznaczenie %>% i wskazuje, że poprzedzające go dane (lub wyjście funkcji) posłużą jako pierwszy argument następnego narzędzia. Zapewnia to bardziej liniowy przepływ i projekt manipulacji danymi. Tidyverse jest napisany, aby umieścić wartości.
Krytyka

Niektórzy programiści uważają, że te cechy składni są albo nieistotne, albo po prostu niepoważne. W szczególności specjalne formy językowe sprawiają, że język jest mniej monotonny, a jego specyfikacja bardziej złożona, i mogą powodować problemy, gdy programy stają się większe. Ta reprezentacja jest szczególnie rozpowszechniona w społeczności Lisp, ponieważ ma bardzo prostą, regularną i powierzchowną składnię, którą można łatwo zmienić.
pojęcia pochodne

Sól składniowa. Metafora została rozszerzona przez wprowadzenie tego terminu, który odnosi się do funkcji zaprojektowanej w celu utrudnienia pisania złego kodu. W szczególności sól składniowa jest obręczą, którą programiści muszą przeskoczyć, aby udowodnić, że wiedzą, co się dzieje, zamiast wyrażać działanie programu. Na przykład w Javie i Pascalu przypisanie wartości zmiennoprzecinkowej do zmiennej zadeklarowanej jako int, bez dodatkowej składni wyraźnie określającej, co jest zamiarem spowoduje błąd w czasie kompilacji, podczas gdy C i C ++ automatycznie obcinają wszystkie liczby zmiennoprzecinkowe przypisane do int. Nie jest to jednak składnia, lecz semantyka.
W C # ukrywanie odziedziczonego członka klasy generuje ostrzeżenie kompilatora, chyba że słowo kluczowe jest używane do wskazania, że ukrywanie jest zamierzone. Ma to na celu uniknięcie możliwych błędów ze względu na podobieństwo przełącznika deklaracji składni do tego w C lub C ++, C # wymaga przerwy dla każdego niepustego przełącznika etykiety przypadku, nawet jeśli nie pozwala na implicite drop.
Sól składniowa może zniweczyć jego cel, czyniąc kod nieczytelnym i tym samym obniżając jego jakość. W skrajnych przypadkach część główna może być krótsza od narzutu wprowadzonego w celu spełnienia wymagań językowych.
Alternatywą dla tego jest generowanie ostrzeżeń kompilatora, gdy istnieje duże prawdopodobieństwo, że kod wydaje się być wynikiem błędu, praktyka powszechna w nowoczesnych kompilatorach C/C ++.
Składnia sacharyna

Kolejnym rozszerzeniem jest również syrop. Oznacza również, podobnie jak sacharyna, nieracjonalną składnię, która nie ułatwia programowania.
Może wydawać się dziwne nazywanie języka "słodkim", ale jeśli pracujesz w Rubyist, jest to uzasadnione. Ten program ma więcej cukru składniowego niż wiele języków, ponieważ kładzie nacisk na zrozumienie przez człowieka, a nie przez komputer. Twórca Rubiego, Yukihiro Matsumoto, chciał uczynić język nie tylko wydajnym, ale i zabawnym. Kompilatory i interpretery mogą lubić ten wysoce ustrukturyzowany, jednoznaczny dział gramatyki, ale ludzie mogą mieć trudności z jego zrozumieniem. Tu właśnie pojawia się cukier syntaktyczny - sprawia, że język jest "słodszy" zarówno w piśmie, jak i w czytaniu.
Pisanie kodu

Ważne jest, aby pamiętać, że "cukier syntaktyczny" nie jest terminem technicznym, ale konstrukcją zaprojektowaną, aby pomóc opisać sposób wyrażania języka. Mówiąc najprościej, termin ten oznacza kod zoptymalizowany dla ludzi. Celem jest uproszczenie składni tak, aby była łatwa do odczytania, nawet jeśli zmniejszy to niektóre z technicznych wyjaśnień. Oczywiście, pisanie słodkiego kodu nie oznacza, że możesz pominąć ważny krok, jakim jest zrozumienie.
Tak jak w prawdziwym życiu, wiedza o tym, ile cukru jest używane, jest ważna dla ogólny stan zdrowia zdrowie. Cukier czyni kod prostym i ekspresyjnym, ale powoduje też niejednoznaczność. Dzieje się tak zazwyczaj dlatego, że nie każdy zna i stosuje to pojęcie podczas programowania.
 Projektowanie zorientowane obiektowo: definicja, zasady i przykłady
Projektowanie zorientowane obiektowo: definicja, zasady i przykłady Męski feminizm: definicja i przykłady z życia
Męski feminizm: definicja i przykłady z życia Co to są płatności różnicujące: definicja, wzór i przykłady obliczeń
Co to są płatności różnicujące: definicja, wzór i przykłady obliczeń Uczciwa konkurencja: definicja, rodzaje i cechy, przykłady
Uczciwa konkurencja: definicja, rodzaje i cechy, przykłady Krytyka jest... Znaczenie, definicja i pochodzenie
Krytyka jest... Znaczenie, definicja i pochodzenie Sieci bayesowskie: definicja, przykłady i zasady działania
Sieci bayesowskie: definicja, przykłady i zasady działania Prawa ashby'ego: treść, definicja, cechy
Prawa ashby'ego: treść, definicja, cechy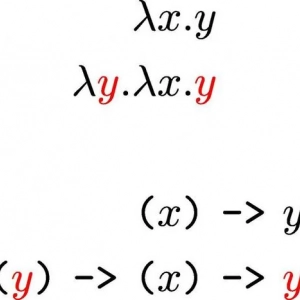 Rachunek lambda: opis twierdzenia, cechy, przykłady
Rachunek lambda: opis twierdzenia, cechy, przykłady Co to jest - kaleka? Definicja, przykłady
Co to jest - kaleka? Definicja, przykłady