Zadowolony
NoSQL to pamięci masowe, które nie są zgodne z modelem relacyjnej bazy danych i ich cechami charakterystycznymi, nie mają schematu, nie łączą się i nie gwarantują własności ACID. System NO skaluje się horyzontalnie i wykorzystuje dużą ilość pamięci głównej komputera, rozwiązując problem dużych ilości informacji.
Własne typy to nowa metodologia tworzenia nierelacyjnych baz danych NoSQL, wdrażana przez duże firmy w celu zaspokojenia potrzeb korporacyjnych, takich jak BigTable od Google, który jest uważany za pierwszy system NoSQL, i Amazon DynamoDB. Sukces tych systemów zapoczątkował rozwój wielu podobnych systemów baz danych typu open source i własnościowych, z których najpopularniejsze to Hypertable, Cassandra, MongoDB, DynamoDB,
Ewolucja bazy danych NoSQL
Problem skalowalności SQL został dostrzeżony przez firmy Web 2.0 ogromnych, rosnących potrzebach w zakresie danych i infrastruktury, takich jak Google, Amazon i Facebook. Znaleźli swoje własne rozwiązywanie problemów, wprowadzenie technologii BigTable, DynamoDB i Cassandra. Rosnące zainteresowanie doprowadziło do powstania szeregu systemów zarządzania bazami danych NoSQL (DBMS), w których nacisk położono na wydajność, niezawodność i spójność. Wiele istniejących struktur indeksowania zostało ponownie wykorzystanych i ulepszonych, aby poprawić wydajność wyszukiwania i odczytu.
Termin ten został ukuty przez Calora Strozziego w 1998 roku i wskrzeszony w 2009 roku przez pracownika Rackspace Erica Evansa, aby rozwiązać problemy firm internetowych z dużą ilością transakcji i informacji.

Jedną z kluczowych różnic pomiędzy bazami NoSQL a tradycyjnymi relacyjnymi bazami danych jest to, że te pierwsze są formą niestrukturalnego przechowywania danych.

NoSQL nie ma więc stałej struktury tabel jak system relacyjny. Ta tabela zawiera krótkie porównanie cech NoSQL i SQL.

Należy zauważyć, że tabela przedstawia porównanie na poziomie bazy danych, a nie na poziomie systemu DBMS, który implementuje oba modele. Systemy te zapewniają własne, zastrzeżone metody przezwyciężania niektórych problemów i niedociągnięć obu systemów, co znacznie poprawia wydajność i niezawodność.
Typy sklepów z informacjami

Typ bazy danych NoSQL Key-Value używa tabeli hash, w której unikalny klucz wskazuje na element. Mogą być zorganizowane w logiczne grupy, wymagające unikalności w ich obrębie. Pozwala to na umieszczenie identycznych kluczy w różnych grupach logicznych. Niektóre implementacje baz danych zapewniają mechanizmy buforowania, które znacznie poprawiają wydajność.
Wszystkie, wymagane do pracy z elementami przechowywanymi w bazie danych jest kluczem. Dane są przechowywane w jako ciąg JSON lub BLOB (duży obiekt binarny). jeden z największy wadą tej formy jest brak spójności na poziomie bazy danych. Może to być dodane podczas rozwoju bazy danych NoSQL przez programistów z własnym kodem, ale wymaga to również więcej wysiłku ze względu na złożoność implementacji i czas. Najbardziej znaną bazą danych NoSQL opartą na magazynie wartości kluczowych jest Amazon DynamoDB.
Magazyny dokumentów są podobne do magazynów klucz-wartość w tym, że nie zawierają schematu i są oparte na modelu wartości. W związku z tym oba typy mają takie same plusy i minusy. W obu przypadkach brakuje spójności na poziomie bazy danych, co uniemożliwia aplikacjom zapewnienie bardziej niezawodnych funkcji. Istnieją jednak pewne kluczowe różnice między nimi. W repozytoriach dokumentów wartości (dokumenty) stanowią kodowanie dla przechowywanych danych. Takim kodowaniem może być XML, JSON lub BSON (kod binarny JSON). Najpopularniejszą aplikacją bazodanową, która wykorzystuje repozytorium dokumentów jest MongoDB.
Kolumnowa baza danych przechowuje dane w kolumnach, a nie w wierszach, jak większość relacyjnych systemów zarządzania bazą danych. Magazyn kolumnowy składa się z jeden lub Kilka rodzin kolumn, które logicznie grupują pewne kolumny razem w bazie danych. Klucz jest używany do identyfikacji i określenia liczby kolumn z atrybutem przestrzeni kluczowej. Każda kolumna zawiera tuple nazw i wartości, uporządkowane i oddzielone przecinkami.
Magazyny kolumnowe mają szybki dostęp do odczytu/zapisu przechowywanych danych. W nim kolumny wiersza odpowiadają pojedynczej kolumnie i są przechowywane jako pojedynczy rekord na dysku. Zapewnia to szybszy dostęp podczas operacji odczytu/zapisu. Najpopularniejsze bazy danych, które wykorzystują przechowywanie kolumn w bazie NoSQL, przykłady to Google BigTable, HBase i Cassandra.
NoSQL Graph Bd wykorzystuje strukturę grafu skierowanego do reprezentacji danych. Graf składa się z krawędzi i węzłów.
Zasada działania bazy danych

NoSQL działa jak plik, który przechowuje wszystkie dane, pozwalają one pracować z ogromną ilością informacji i organizować je tak, aby użytkownicy mieli do nich dostęp zawsze, gdy tego potrzebują. Istnieją obecnie różne typy NoSQL, każdy działa inaczej, większość jest napisana w C ++. Można powiedzieć, że bazy danych NoSQL wypośrodkowują swoje funkcje w oparciu o:
- Skalowalność pozioma z możliwością zwiększenia jej rozmiaru, zwiększenia przestrzeni dyskowej w bazie danych bez kompromisów do pracy.
- Technologia chmury. Większość baz danych NoSQL opiera swoje przechowywanie w chmurze, aby zwolnić więcej miejsca. Ponadto posiadają węzły do replikacji informacji.
- Efektywne wykorzystanie zasobów. Firmy są obecnie w trakcie transformacji technologicznej, więc posiadanie bazy danych, która pozwala na wdrażanie nowych narzędzi technologicznych jest niemal koniecznością. Dane NoSQL właśnie tak działają - elastyczny model pozwala na szybkie dostosowanie do nowych narzędzi.
- Program swobodnego funkcjonowania. NoSQL nie mają sztywnego systemu, więc programiści mają swobodę zmiany danych w zależności od potrzeb. Oznacza to, że jeśli trzeba zmienić definicję pola lub typu danych, nie ma problemu, w przeciwieństwie do baz danych SQL, gdzie zmiany tego typu wiążą się z dużą złożonością.
- Szybkość reakcji. Szybkość bazy danych jest mierzona przez opóźnienie, czyli czas odpowiedzi, NoSQL zależy na zmniejszeniu opóźnienia w jak największym stopniu.
- Używanie indeksów. SQL i NoSQL potrzebują indeksów, ponieważ zapytania nie mogą być wykonywane w milionach rekordów, jeśli indeks nie został skonfigurowany. W NoSQL indeksy są generowane w formie B-Tree, czyli węzły są zbalansowane, przez co zwiększa się szybkość wyszukiwania.
Systemy kontroli
Poniższa tabela przedstawia krótkie porównanie różnych systemów zarządzania bazami danych NoSQL.

MongoDB posiada elastyczny magazyn schematów - oznacza to, że przechowywane obiekty nie muszą mieć tej samej struktury lub pól. Posiada również pewne funkcje optymalizacyjne, które dystrybuują zbiory danych między sobą, co skutkuje ogólną lepszą wydajnością i bardziej zrównoważonym systemem. Inne systemy Bazy NoSQL, takie jak Apache CouchDB, są również bazami danych typu document store i dzielą wiele cech z MongoDB, z wyjątkiem tego, że dostęp do bazy danych można uzyskać za pomocą RESTful API.
REST to styl architektoniczny składający się ze skoordynowanego zestawu ograniczeń architektonicznych stosowanych do komponentów, łączników i elementów danych w Internecie. Opiera się na buforowalnym protokole komunikacyjnym "klient - serwer" bez trwałości stanu, np. protokół HTTP. Aplikacje RESTful używają żądań HTTP do publikowania, czytania i usuwania danych. Jeśli chodzi o kolumnowe bazy danych, Hypertable to baza danych NoSQL napisana w C ++ i oparta na Google BigTable. Hypertable wspiera dystrybucję węzłową magazynów danych dla maksymalnej skalowalności, jak MongoDB i CouchDB.
System hybrydowy Cassandra

Jedną z najczęściej używanych baz danych NoSQL jest Cassandra, opracowana przez Facebooka. Celem Cassandry było stworzenie DBMS, który nie ma pojedynczego punktu awarii i zapewnia maksymalną dostępność. Cassandra jest przede wszystkim kolumnową bazą danych. W niektórych opracowaniach wymieniany jest jako system hybrydowy oparty na Google BigTable, który jest bazą danych typu columnar storage oraz Amazon DynamoDB, który jest typu key-value. Klucze w Cassandrze wskazują na zestaw rodzin kolumn polegających na funkcjach dostępności rozproszonego systemu plików Google BigTable i Dynamo (rozproszona tablica haszująca).
Do głównych cech Cassandry należą:
- Brak pojedynczego punktu awarii. Aby to zrobić, musi działać na klastrze węzłów, a nie na pojedynczej maszynie. Nie oznacza to, że dane na każdym klastrze są takie same. Gdy nastąpi awaria w jednym z węzłów, dane na tym węźle będą niedostępne. Jednak inne węzły i dane będą nadal dostępne.
- Rozproszone haszowanie jest schematem, który zapewnia funkcjonalność tablicy haszującej w taki sposób, że dodanie lub usunięcie pojedynczego gniazda nie zmienia znacząco mapowania klucza do gniazd. Pozwala to na zrównoważenie obciążenia serwerów lub węzłów w zależności od pojemności i zminimalizowanie przestojów.
- Stosunkowo łatwy w użyciu interfejs klienta. Używa Apache Thrift dla swojego interfejsu klienta, który zapewnia klienta RPC w kilku językach, ale większość programistów woli alternatywy open-source oparte na Apple Thrift, takie jak Hector.
- Replikacja danych. W istocie, odzwierciedla on dane dla innych węzłów w klastrze. Replikacja może być losowa lub zdefiniowana w celu maksymalizacji ochrony danych, np. poprzez współlokację na węźle w innym centrum danych.
- Polityka partycjonowania decyduje o tym, gdzie i na którym węźle umieszczony jest klucz. Może to być proces losowy lub uporządkowany. Dzięki obu typom polityk partycjonowania Cassandra może znaleźć równowagę między obciążeniem pracą a zoptymalizowaną wydajnością zapytań.
- Spójność. Replikacja utrudnia zachowanie spójności. Dzieje się tak dlatego, że wszystkie węzły muszą być w każdej chwili aktualizowane najnowszymi wartościami lub podczas operacji odczytu.
- Czynności odczytu/zapisu. Klient wysyła zapytanie do pojedynczego węzła. Węzeł przechowuje dane w klastrze zgodnie z polityką replikacji. Każdy węzeł najpierw zmienia dane w commit logu i aktualizuje strukturę tabeli, obie zmiany są wykonywane synchronicznie. Żądanie odczytu jest wysyłane do jednego węzła, który zawiera dane zgodnie z polityką podziału/umieszczenia.
Struktury indeksujące

Indeksowanie to proces kojarzenia klucza z lokalizacją odpowiadającego mu rekordu danych w bazie danych. Istnieje wiele struktur indeksowania używanych w bazach NoSQL. B-Tree jest jednym z najczęściej spotykany struktury indeksów w DBMS. W nim węzły wewnętrzne mogą mieć zmienną liczbę węzłów podrzędnych w określonym zakresie.
Jedną z głównych różnic w stosunku do innych struktur drzewiastych, takich jak AVL, jest to, że B-Trees pozwala na zmienną liczbę węzłów dziecięcych, co oznacza mniejszą równowagę drzewa, ale większą stratę miejsca. B + Tree jest jednym z najbardziej popularnych wariantów B-trees. To ulepszenie (w przeciwieństwie do B-Tree) wymaga, aby wszystkie klucze znajdowały się w liściach.
Struktura danych T-Trees została opracowana poprzez połączenie funkcji AVL-Trees i B-Trees. Drzewa AVL są samobalansującymi się drzewami wyszukiwania binarnego, podczas gdy drzewa B są niezbalansowane, a każdy węzeł może mieć inną liczbę dzieci.
T-Tree ma bardzo podobną strukturę do AVL-Tree i B-Tree. Każdy węzeł przechowuje więcej niż jedną krotkę {klucz-wartość, wskaźnik}. Ponadto wyszukiwanie binarne jest używane w połączeniu z węzłami i wieloma krotkami, aby zapewnić lepszą pamięć i wydajność.
Drzewo T ma trzy rodzaje węzłów: z prawym i lewym dzieckiem, węzeł końcowy bez dzieci oraz węzeł półliścia z jednym dzieckiem. Mówi się, że T-Trees ma najlepszą ogólną wydajność.
Częste błędy w korzystaniu z bazy danych
Istnieją trzy powszechne błędy, które organizacje popełniają, gdy chodzi o NoSQL:
- NoSQL to coś więcej niż skalowalność, nie można utożsamiać NoSQL ze skalą internetową. Protoplastami nowoczesnych nierelacyjnych baz danych były firmy takie jak Google i Amazon, które skupiły się na rozwiązywaniu problemów skalowalności w środowisku internetowym.
- Deweloperzy muszą się rozwijać. W jednym z projektów internetowych wysokiej klasy, źle dobrany zespół integracyjny stworzył ogromny problem, a jego rozwiązanie zajęło czas i miliony dolarów.
- Skomplikowane rozmnażanie. Nie ma substytutu dla wiedzy specjalistycznej w zakresie wdrażania lub administracji. Czasami zapytanie, które działa szybko na lokalnej maszynie deweloperskiej, nie skaluje się horyzontalnie na setkach maszyn. Nowoczesna aplikacja ma rozproszoną architekturę i wielu użytkowników jednocześnie, którzy wymagają szybkich odpowiedzi.
Zalety NoSQL
Bazy danych NoSQL i SQL konkurują ze sobą, ale według wielu ekspertów te pierwsze mają więcej zalet niż tradycyjne relacyjne bazy danych:
- Mają prostą i elastyczną strukturę.
- Brak schematu.
- Na podstawie par "klucz-wartość".
- Niektóre typy obejmują kolumny, dokument, klucz-wartość, wykres, obiekt, XML i inne tryby danych.
- Zazwyczaj każda wartość w bazie danych ma klucz. Niektóre repozytoria pozwalają programistom na przechowywanie serializowanych obiektów, a nie tylko prostych wartości łańcuchowych.
- Otwarte źródła NoSQL nie wymagają drogich opłat licencyjnych i mogą być uruchamiane na niedrogim sprzęcie, co sprawia, że ich wdrożenie jest opłacalne.
- Dzięki NoSQL, niezależnie od tego, czy są to bazy open source czy własnościowe, ekspansja jest łatwiejsza i tańsza, niż w przypadku pracy z z relacyjnymi bazami danych. Odbywa się to poprzez skalowanie poziome i rozkładanie obciążenia na wszystkie węzły, a nie jak to zwykle bywa w systemach relacyjnych baz danych poprzez pionowe skalowanie, które polega na zastąpieniu głównego hosta bardziej wydajnym.
Wady NoSQL
Bazy danych NoSQL działają różnie, wszystko zależy od przechowywanych w nich dokumentów, ale można powiedzieć, że są ważnym narzędziem w nowoczesnych firmach, ponieważ przechowują niezbędne informacje o użytkownikach i transakcjach.
Nie są one doskonałe, więc nie zawsze są właściwy wybór dla programistów. С z jednej strony, większość z nich nie obsługuje funkcji niezawodnościowych, które z natury obsługują relacyjne systemy baz danych. Te cechy niezawodności można podsumować jako atomowość, spójność, izolację i trwałość. Oznacza to, że bazy NoSQL, które nie obsługują tych funkcji, sprzedają spójność za wydajność i skalowalność.
Aby obsługiwać funkcje niezawodności i spójności, programiści muszą implementować własny, zastrzeżony kod, co zwiększa złożoność systemu. To ogranicza liczbę aplikacji, które mogą polegać na NoSQL dla bezpiecznych i niezawodnych transakcji, takich jak systemy bankowe.
Korzystanie z bazy danych NoSQL

Pracownicy naukowi, inżynierowie, architekci oprogramowania, projektanci aplikacji i programiści wymagają głębszej wiedzy na temat struktur danych, która nie była wcześniej wymagana w przypadku relacyjnych baz danych. Liderami rynku są Hadoop i MongoDB, a następnie "Cassandra", "Radice", CouchDB i "Riacom". Obecne badania pokazują, że istnieją dwa produkty NOSQL, które dominują wśród inżynierów systemów, architektów oprogramowanie, deweloperzy wśród kilkunastu podobnych technologii są MongoDB i Hadoop.
Rynek pokazuje, że duże firmy stosują nowe metodologie rozwoju baz danych NoSQL i integrują je ze swoimi produktami (Oracle, IBM). Rynek baz danych powoli staje się standardem dzięki PasS, Redis i MongoDB, Edlich. Produkty takie jak Neo4j, MongoDb i CouchDb zostały skierowane do wsparcia i inwestycji venture capital.
 Relacyjne dbms: przegląd bazy danych, przykłady
Relacyjne dbms: przegląd bazy danych, przykłady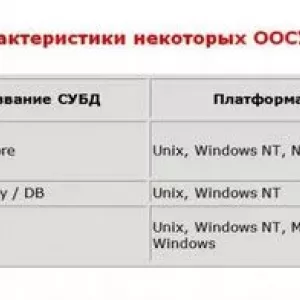 Obiektowe bazy danych: pojęcie, podstawowe pojęcia, zarządzanie, przykłady
Obiektowe bazy danych: pojęcie, podstawowe pojęcia, zarządzanie, przykłady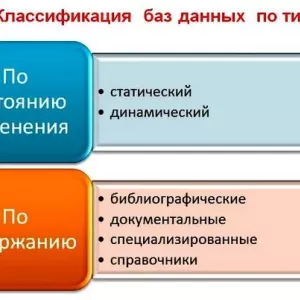 Klasyfikacja baz danych: opcje, modele danych i kluczowe cechy
Klasyfikacja baz danych: opcje, modele danych i kluczowe cechy Węzeł nieskończoności: znaczenie i przykłady zastosowania
Węzeł nieskończoności: znaczenie i przykłady zastosowania Dobra pasta do zębów wrażliwych: przegląd producentów, szczegóły dotyczące zastosowania
Dobra pasta do zębów wrażliwych: przegląd producentów, szczegóły dotyczące zastosowania Ogólne zasady sylogizmu: przykłady zastosowania, definicja, kolejność i sposób rozumowania
Ogólne zasady sylogizmu: przykłady zastosowania, definicja, kolejność i sposób rozumowania Klej do płytek winylowych: przegląd producentów, cechy zastosowania
Klej do płytek winylowych: przegląd producentów, cechy zastosowania Pisownia słowa odwrócić. Przykłady zastosowania
Pisownia słowa odwrócić. Przykłady zastosowania Szampony dermatologiczne: przegląd produktów, cechy zastosowania, skuteczność
Szampony dermatologiczne: przegląd produktów, cechy zastosowania, skuteczność